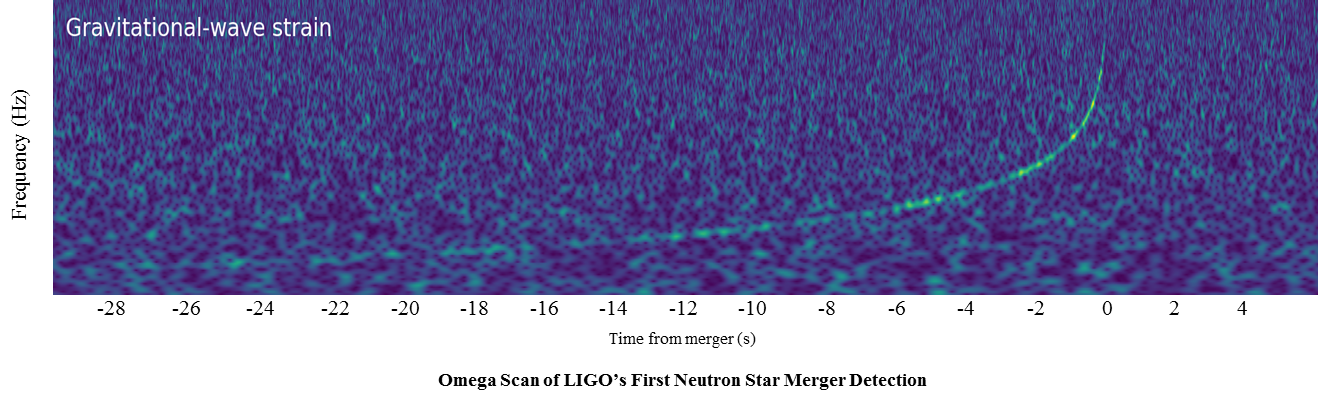
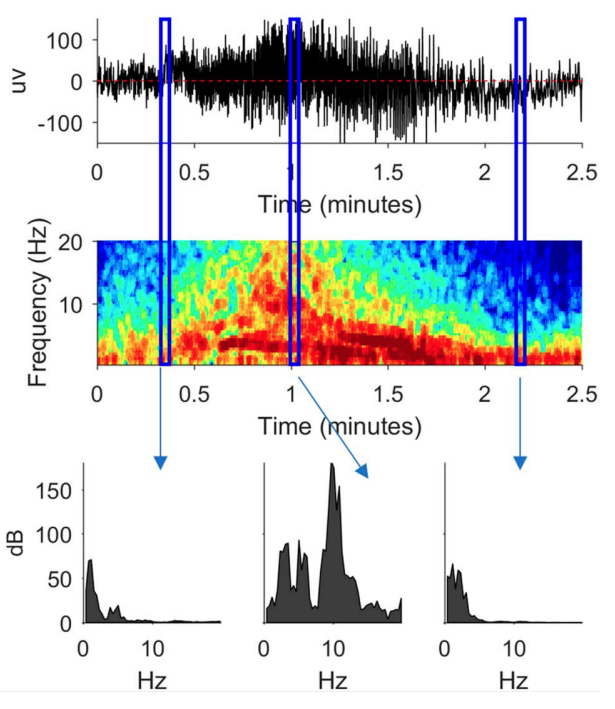
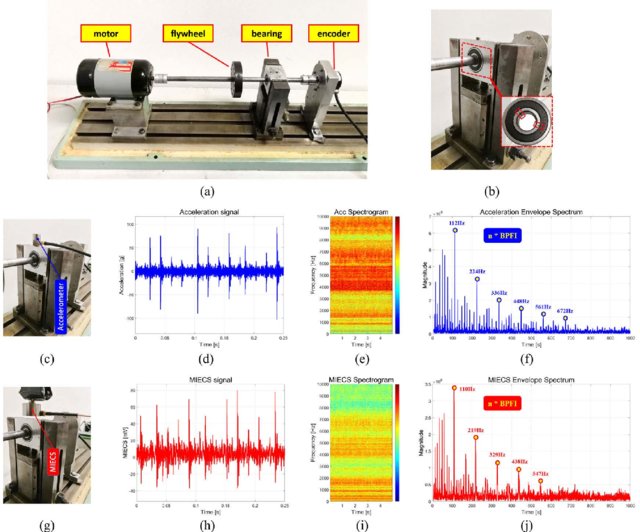
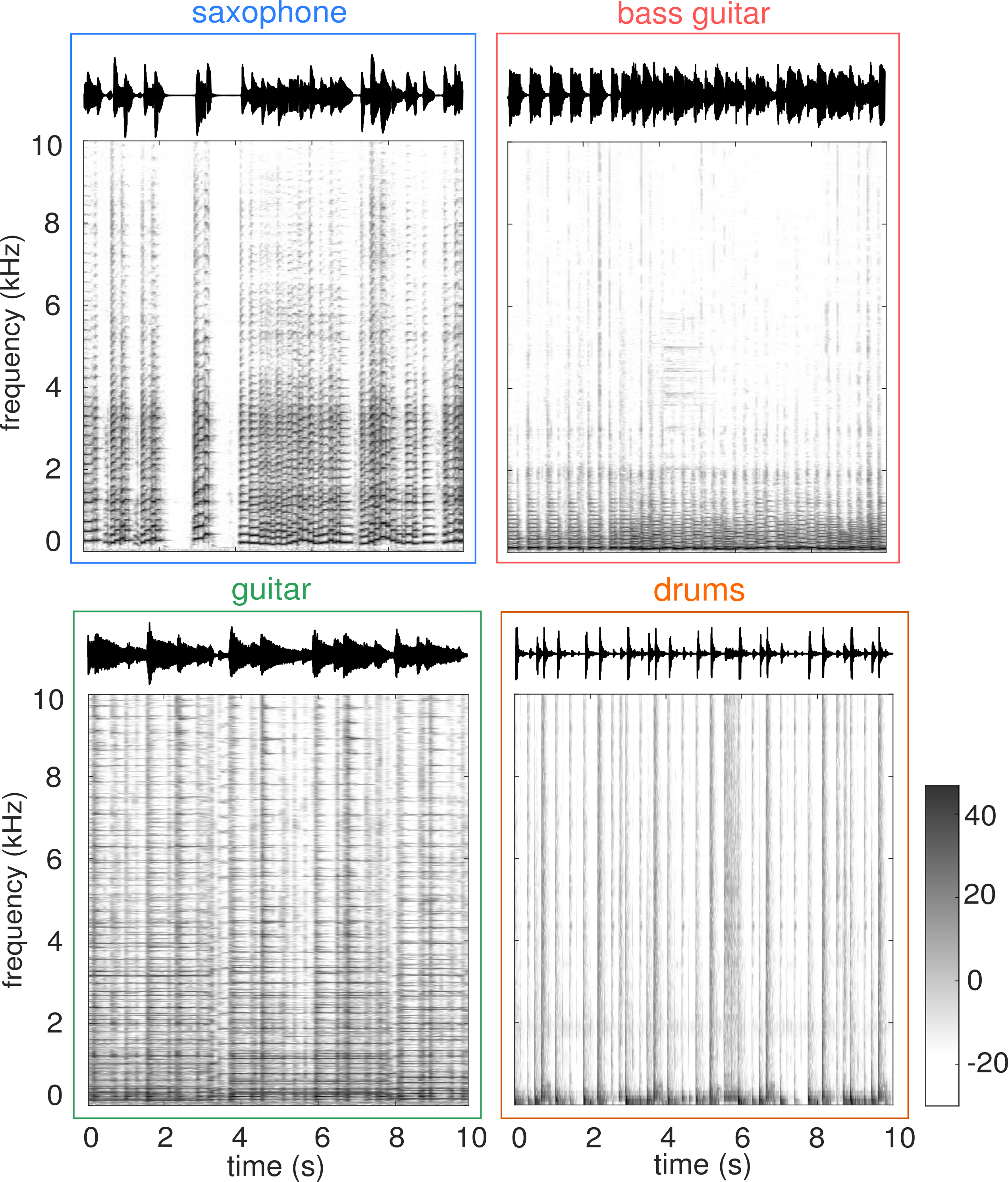
Geometric interpretation and alternatives to the DFT¶
To finish this part, let's discuss about a geometric interpretation of the DFT. This is probably what you should really remember about the DFT, because it shares strong connections with other aspects of signal representations that will be discussed in following lessons.
Let $\mathbf{x} \in \mathbb{R}^T$ be the vector representation of the signal $x(t)$, $t \in \{ 0,...,T-1 \}$, and let $\mathbf{u}_f \in \mathbb{C}^T$ be the vector of entries $\mathbf{u}_f(t) = \frac{1}{\sqrt{F}} \exp\left(+j 2 \pi \frac{f t}{F}\right)$, $t \in \{ 0,...,T-1 \}$. This vector can be regarded as a complex sinusoid of frequency $f/F$, using Euler's formula:
$$ e^{+j 2 \pi \frac{f t}{F}} = \cos\left( 2 \pi \frac{f t}{F} \right) + j \sin\left( 2 \pi \frac{f t}{F} \right). $$
Then the (normalized) DFT can be expressed as inner products (on the complex vector space $\mathbb{C}^T$) between the signal $\mathbf{x}$ and complex sinusoids $\mathbf{u}_f$ of different frequencies:
$$ X(f) = \langle \mathbf{x}, \mathbf{u}_f \rangle = \mathbf{u}_f^H \mathbf{x}, \qquad f \in \{0,...,F-1\}, $$
where $\cdot^H$ denotes Hermitian transpose (transpose + complex conjugate).
If we assume that $F = T$ (after zero-padding or truncation), the vector $\check{\mathbf{x}} \in \mathbb{C}^F$ of DFT coefficients is obtained by multiplying the signal $\mathbf{x} \in \mathbb{R}^T$ with the DFT matrix $\mathbf{U} \in \mathbb{C}^{F \times T}$ where each row of index $f \in \{0,...,F-1\}$ is defined by ${\mathbf{u}_f^H \in \mathbb{C}^T}$:
$$ \check{\mathbf{x}} = \mathbf{U} \mathbf{x}, \qquad (\mathbf{U})_{f,:} = \mathbf{u}_f^H. $$
The figure below shows the real (left) and imaginary (right) parts of the DFT matrix:
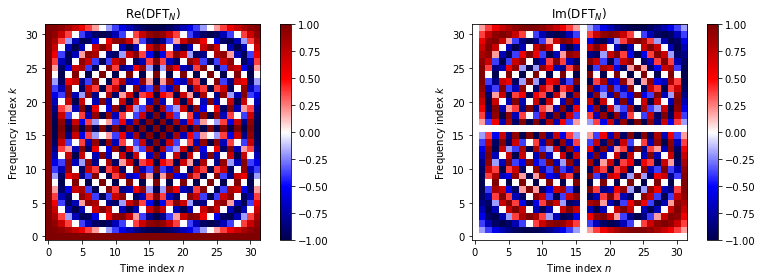
Image credit: Meinard Müller, “Fundamentals of Music Processing”, Springer 2015